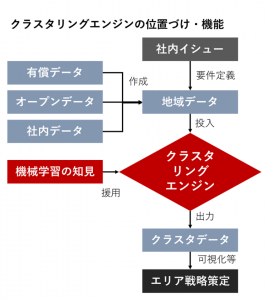
私たちの計算システム「クラスタリングエンジン」 では、大量の地域データをグループ分けすることができます。
このエンジンでは、町丁目やメッシュなどで集計されたデータや、緯度経度のついた個票データを、一定の機械学習アルゴリズムに従って分類します。結果として、場所ごとに異質である地域の性質を一目に明らかにすることができます。
可視化などを行えば、迅速かつ適切なエリア戦略に役立ちます。
クラスタリングエンジンは確立された機械学習の知見に基づいており、下記の論文で提唱された手法を用いています。
- Arthur, D., & Vassilvitskii, S. (2007). k-means : the advantages of careful seeding. Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms, (pp. 1027–1035).
- Cattell, B., R. (1966). The scree test for the number of factors. Multivariate Behavioral Research 1, 245-276.
- Dan, P., & Moore, A. (2000). X-means: Extending K-means with Efficient Estimation of the Number of Clusters. ICML ’00 Proceedings of the Seventeenth International Conference on Machine Learning, (pp. 727-734).